In Finland, vehicle registration plates consist of three letters and three numbers separated with a dash (e.g. ORA-600), there is actually a real car (a Saab) with this license plate. For 1000€ one can buy a vanity plate with 2-3 letters and 1-3 numbers.
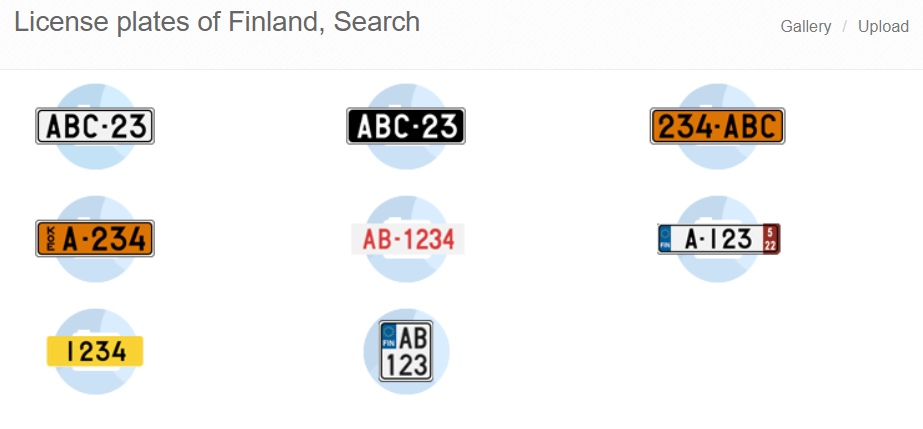
Often, in application forms, etc., you are asked to type your 6 character license plate and most of us insert it without the dash. How about if you want the application to be automatically able to show it (when needed) with the dash (even if the field is varchar2(6))? Here is an example showing a new feature of Oracle Database 23c called SQL Domains.
A SQL domain is a dictionary object that belongs to a schema and encapsulates a set of optional properties and constraints for common values, such as credit card numbers, registration plates or email addresses. After you define a SQL domain, you can define table columns to be associated with that domain, thereby explicitly applying the domain’s optional properties and constraints to those columns.
With SQL domains, you can define how you intend to use data centrally. They make it easier to ensure you handle values consistently across applications and improve data quality.
SQL Domains allow users to declare the intended usage for columns. They are data dictionary objects so that abstract domain specific knowledge can be easily reused.
We will use the CREATE DOMAIN command to create a SQL domain where the domain must specify a built-in Oracle datatype (think of annotation as an extended comment):
SQL> create domain reg_plate as varchar2(6)
constraint check (length(reg_plate) >=3)
display (substr(reg_plate,1,3)||'-'||substr(reg_plate,4,3))
annotations (title 'regplateformat');
Domain created.After we defined our SQL domain reg_plate we will define table column(s) to be associated with that domain. In our case this is the registration_plate column. Thus, we declare via the SQL Domain the intended usage for the column(s).
SQL> create table car_owners
( id number(5),
name varchar2(50),
car_brand varchar2(20),
registration_plate varchar2(6) DOMAIN reg_plate
)
annotations (display 'car_owners_table'); Now, have a look the the type of the column registration_plate:
SQL> desc car_owners
Name Null? Type
---------------------- -------- ----------------------------
ID NUMBER(5)
NAME VARCHAR2(50)
CAR_BRAND VARCHAR2(20)
REGISTRATION_PLATE VARCHAR2(6) JULIAN.REG_PLATELet us insert a row into the table so that the license plate will be without the dash:
SQL> insert into car_owners values (1,'JULIAN','LEXUS','ORA600');
1 row created.
SQL> commit work;
Commit complete.With the new function DOMAIN_DISPLAY we can display the property meaning we can force the dash to be used in the output:
SQL> select DOMAIN_DISPLAY(registration_plate) from car_owners;
DOMAIN_DISPLAY(REGISTRATI
-------------------------
ORA-600Dropping SQL domains is almost like dropping tablespaces, you need first to drop the objects associated with the SQL domain:
SQL> drop domain reg_plate;
drop domain reg_plate
*
ERROR at line 1:
ORA-11502: The domain to be dropped has dependent objects.You can drop though the domain using the FORCE mode, similar to drop tablespace including contents and datafiles.
SQL> drop table car_owners purge;
Table dropped.
SQL> drop domain reg_plate;
Domain dropped.The new dictionary views associated with SQL domains are USER_DOMAIN_COLS and USER_DOMAINS. Of course you have the corresponding DBA_ and ALL_ views. USER_ANNOTATIONS_USAGE provides usage information about the annotations owned by the current user. Tim Hall has just published a blog post on annotations, have a look. He said it very well: we can think of annotations as an extension of database comments. I would recommend reading (at least) the end of his blog post on SQL Domains.