“From my experience, the best advisors help in three ways: encourage you to look at the problem or opportunity from multiple angles; help you balance the tug of the short-term with important long-term priorities; and ask the tough questions you need to know to reach the best solution.” Margo Georgiadis
The Oracle Segment Advisor identifies segments that have space which can be reclaimed. However, the Automatic Segment Advisor can be at times resource consuming and even slow down your database:

Why is this happening granted the Automatic Segment Advisor does not analyze every database object? Here is how it works internally: the advisor examines the database statistics, it samples segment data, and then selects the following objects to analyze:
- Tablespaces that have exceeded a critical or warning space threshold
- Segments that have the most activity
- Segments that have the highest growth rate
In addition, the Automatic Segment Advisor evaluates tables that are at least 10MB in size and have at least 3 indexes to determine the amount of space saved if the tables are compressed with advanced row compression.
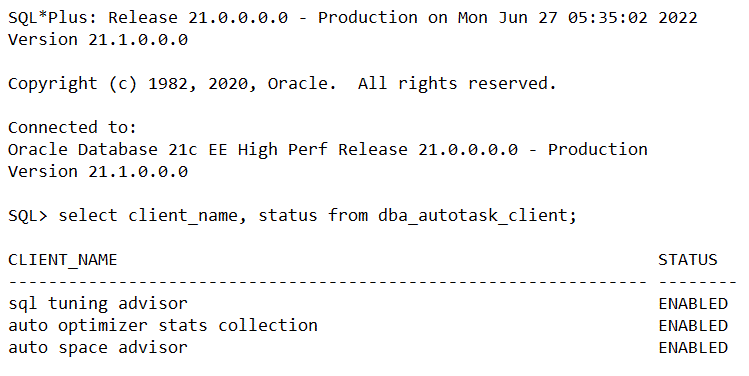
Now, here is the important part: if a database object is selected for analysis by the advisor but the maintenance window expires before the advisor can process the object, the object is included in the next Automatic Segment Advisor run. So, at one point you may come to a situation where lots of objects have to be analyzed. During the maintenance window, the following clients/task are being run, these are the predefined automated maintenance tasks:
Sometimes, it makes sense to disable the auto space advisor as you cannot change the set of tablespaces and segments that the Automatic Segment Advisor selects for analysis. You can, however, enable or disable the Automatic Segment Advisor task, change the times during which the Automatic Segment Advisor is scheduled to run, or adjust automated maintenance task system resource utilization. Especially in a situation like this:

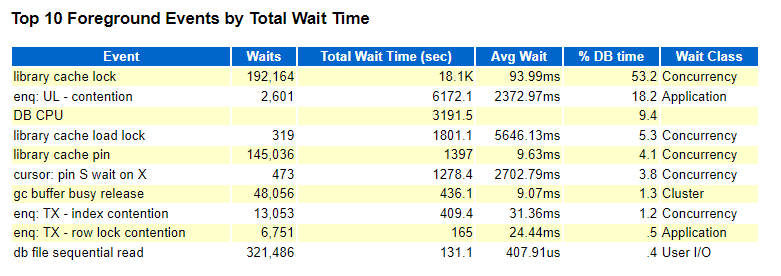
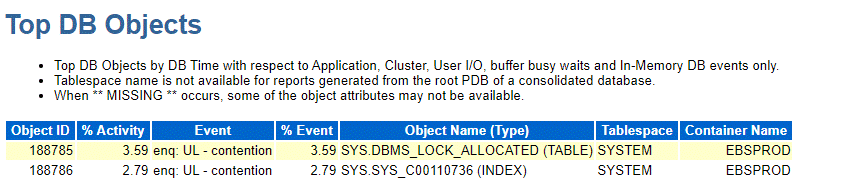
Often, also ADDM may point out to the problem with the Automatic Segment Advisor task:

Here is how to disable (and enable) the tasks individually. The main switch is controlled by DBMS_AUTO_TASK_ADMIN.DISABLE().

Even after disabling the entire autotask job by running DBMS_AUTO_TASK_ADMIN.DISABLE(), the DBA_AUTOTASK_TASK will still show autotask client as enabled. For this you need to disable the jobs individually as shown above. And for a multitenant environment, CDB and PDBs have their own autotasks, disabling CDB’s autotask will not affect the PDBs, so you will have to do for each pluggable database.
Staring with 12.2, there is a parameter called ENABLE_AUTOMATIC_MAINTENANCE_PDB that can be used to enable or disable the running of automated maintenance tasks for all the PDBs in a CDB or for individual PDBs in a CDB. Changing ENABLE_AUTOMATIC_MAINTENANCE_PDB in the CDB root from TRUE to FALSE, the new value FALSE takes effect in the root and in all the PDBs in the CDB.
If you get into a situation where the Automatic Segment Advisor is consuming lots of resource and slowing the database during the maintenance windows do one of the following:
- Disable the autotask client for the segment advisor and run it manually on per need basis.
- Increase the maintenance window from the default which starts at 10 p.m. on Monday to Friday and ends at 2 a.m. Often 4 hours in just not enough. The weekend window is 20h long and in most cases long enough.
In the autonomous database, you have access to dba_autotask_client, etc. and you can disable and enable the auto space advisor task however you do not have full visibility on dba_scheduler_window_groups, etc. Some columns just show as NULL. Still the performance task in ADB can give you some idea of what is going on:

And finally, here are some other situations that might require disabling the Auto Space Advisor Job:
- ORA-01555 While Running Auto Space Advisor Job on Object wri$_adv_objspace_trend_data (Doc ID 2576430.1)
- Auto Space Advisor job may sometimes cause deadlock (Doc ID 17234189.8)
- Auto Space Advisor is Taking More Time due to Recursive Query Taking a Long Time (Doc ID 2382419.1)
- In 12.2 Auto Space Advisor Job Fails With ORA-60 (Doc ID 2321020.1)
- SEGMENT ADVISOR not working as expected for LOB or SYS_LOB SEGMENT (Doc ID 988744.1)